

In the continuously evolving world of artificial intelligence, Large Language Models (LLMs) have emerged as gateways to a realm where machines can understand and mimic human language with astounding accuracy. These incredible constructs invite those of us deeply rooted in the world of AI into new conversations and deeper understanding. Today, I invite you along on a journey where we will explore what "billions" truly represent in the context of LLMs, unpack the science behind quantization, and offer guidance on identifying quantized models. Let's dive in together, shall we?
The Intrigue of "Billions" in LLMS
When we talk about LLMs, "billions" comes up a lot—but what are we really referring to here? It’s elegantly simple yet profoundly complex. The "billions" in LLMs refer to the number of parameters in the model. Think of these parameters as the neurons of a virtual brain, through which the model forms understanding and generates text.
A model with billions of parameters boasts a vast mental arena, capable of grasping subtlety in language patterns and producing responses with depth and nuance. It's like having a conversation with someone well-read and attentive; the exchange feels richer for the diversity of impressions they bring to the table.
Yet, scaling up to such magnitudes introduces a dance with complexity and resource demands. Training these large models is computationally expensive, and deploying them requires significant memory and energy. Here lies the balancing act—achieving great capacity without overstepping practical limitations. Reflecting on this balance nudges us to consider how we define progress in AI.
What is Quantization?
I've written before about quantization when using self-hosted LLMs. Now, let’s demystify quantization—an elegant solution carved out of necessity. At its heart, quantization is about efficiency, smartly reducing the resolution with which a model’s parameters are represented. Typically, models use 32-bit floating-point (FP) numbers, but quantization allows for representation in 8-bit or even 4-bit integers. It’s akin to choosing the right brush strokes when painting a picture, capturing the essence without the excess.
This means that each 32-bit FP "neuron" that use to take 4 bytes of memory, for the 8-bit quantized version only takes 1 byte, 75% less memory, now multiply that by billions of neurons, that's a lot of memory to be used by the LLM model besides the operating system normal memory footprint.
How Is Quantization Employed?
Let’s imagine two main roads for applying quantization: during training and inference. In the training realm, quantization-aware approaches mimic reduced precision methods, ensuring the model's effectiveness remains intact even when fully quantized later. During inference, there's a tangible reduction in memory footprint, allowing models to run swifter.
The benefits of quantization become particularly apparent in devices with limited resources, such as smartphones. The reduction in size and complexity opens up doors, making sophisticated AI more widely accessible and ensuring our everyday tech experiences enrich and empower.
Benefits of Quantization
- Enhanced Efficiency: By lessening data size, quantized models lighten the load, allowing for faster computational speeds. This efficiency is like the wind at your back in real-time systems, pushing forward progress without encumbrance.
- Reduced Energy Consumption: Energy efficiency is a virtue beyond convenience; it’s a nod to sustainability. Smaller models require less energy, aligning well with the growing imperative for responsible technology use.
- Increased Accessibility: With reduced complexity, quantized models enable deployment on a wide spectrum of devices, leveling the playing field in AI accessibility and sparking innovation across diverse sectors.
How to Identify a Quantized Model
Now, with quantization well-explained, how do you spot a quantized model in the wild?
- Model File Size: A clear giveaway is size. Quantized models are generally smaller, owing to their reduced precision nature.
- Documentation and Metadata: Like a book that holds the secrets to its plot in its index, the documentation often reveals whether quantization was applied.
- Performance Characteristics: Watch for swiftness in execution. A model running more briskly may be quantized. Recognizing variations in accuracy alongside speed can offer further insight.
- Framework Support: Our trusty machine learning frameworks like TensorFlow and PyTorch offer specific tools for quantization. Familiarity with these resources can prove helpful in identifying quantized models.
Let's look at Google's Gemma model at Hugging Face
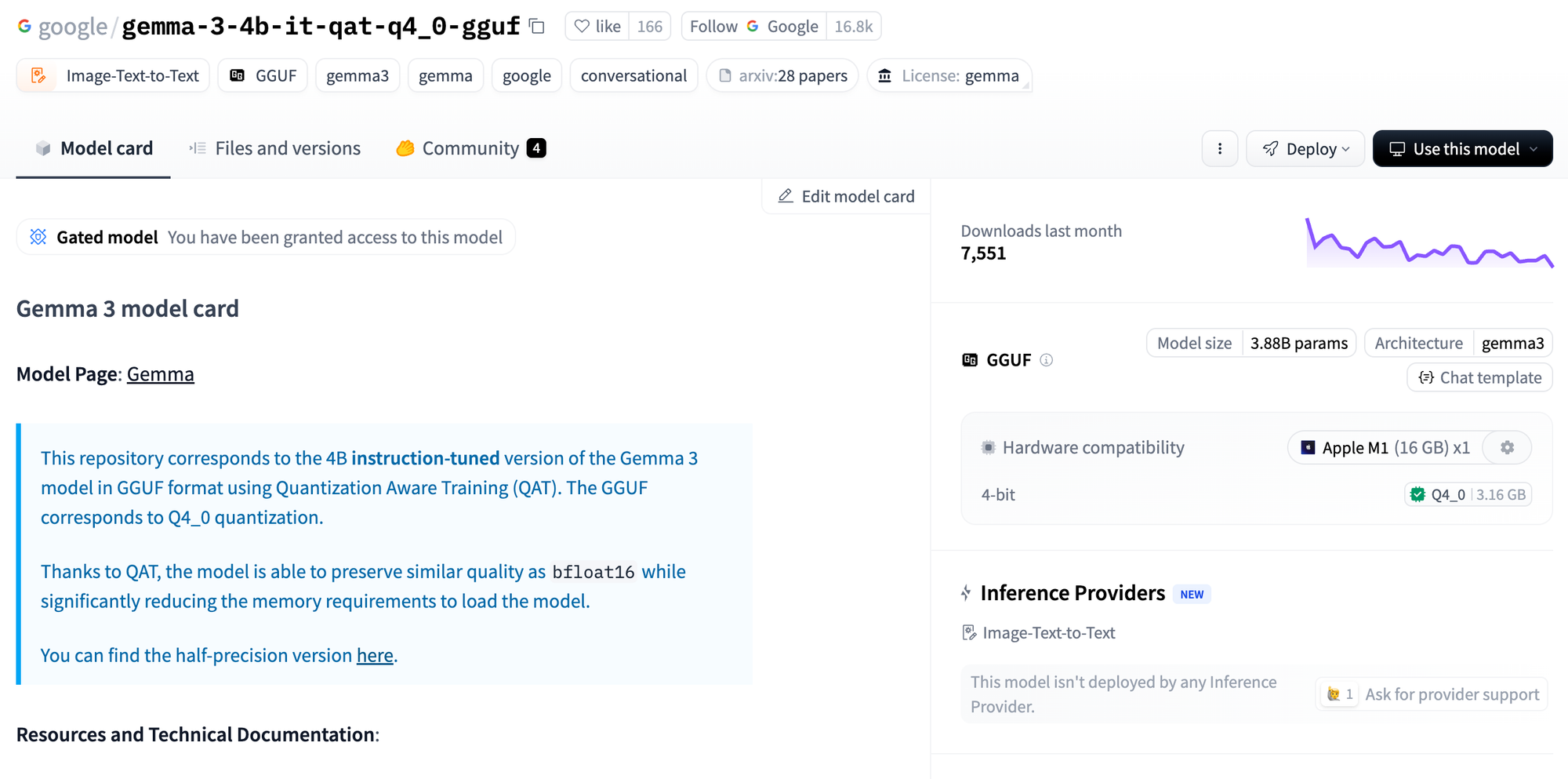
Let's break down the parameters in the model name "gemma-3-4b-it-qat-q4_0-gguf" in Hugging Face:
- gemma: The name of the model.
- 3: This number refers to the model's generation or version.
- 4b: The model size. "4b" stands for 4 billion parameters. The number of parameters is a key indicator of a model's complexity and potential performance.
- it: This abbreviation probably stands for "instruction tuning." Instruction tuning is a training method where a language model is fine-tuned on a dataset of instructions and desired outputs. This helps the model become more capable of following user instructions and completing tasks.
- qat-q4_0: This section indicates quantization and its level.
- qat likely means "Quantization Aware Training." This is a technique used to compress models by reducing the precision of the parameters (e.g., from 32-bit float to 8-bit integer).
- q4_0 specifies the quantization level. "q4" might refer to a particular quantization scheme, and "_0" could denote a specific configuration or level within that scheme.
- gguf: The native format for the llama.cpp library. You can find MLX instead, which is the a new AI/ML framework for Apple Silicon chips.Reflecting on the Journey
Some potential drawbacks of quantized LLMs
While quantization offers several advantages, including reduced model size and increased efficiency, it also comes with some drawbacks, particularly when applied to LLMs. Here are my top 3 drawbacks, there are others but based on my research these are the ones that you need to be aware of:
- Loss of Precision: Quantization reduces the precision of the model's parameters, which can lead to a degradation in the model's performance. This can be particularly problematic for tasks that require high accuracy or subtle understanding, as the model might not perform as well as its full-precision counterpart.
- Accuracy Trade-offs: Depending on the extent of quantization (e.g., moving from 32-bit to 8-bit), there might be significant trade-offs in accuracy. The process can impact the model's ability to capture and represent complex language patterns, leading to less precise outputs.
- Potential for Bias Amplification: Any inherent biases in the training data can become more pronounced in a quantized model if not carefully addressed, as the reduced precision might impact how subtle corrections and nuances in data are handled.
Despite these drawbacks, quantization remains a valuable tool for making large language models more accessible and efficient, especially when careful techniques and strategies are employed to mitigate its limitations.
How Quantization helps to democratize access to LLMs.
The democratization of AI, driven by advancements like quantization, holds transformative potential across various sectors:
- Healthcare: AI democratization enables smaller clinics and remote healthcare providers to access powerful diagnostic tools that were once limited to major hospitals. This includes AI-driven imaging analysis and predictive analytics for patient care, which helps improve outcomes and reach underserved populations.
- Education: In the education sector, democratization allows schools with limited resources to integrate AI tutoring and personalized learning experiences into their curricula. Interactive AI systems can adapt to individual learning paces, helping students grasp complex subjects more effectively.
- Agriculture: Small-scale farmers benefit from accessible AI tools for crop monitoring and yield prediction, which were traditionally available only to large corporations. AI-powered apps can provide insights on soil health, pest management, and weather forecasting, optimizing productivity and sustainability.
- Retail: Smaller retailers now have access to sophisticated AI-powered tools for inventory management, personalized marketing, and customer service automation. These systems help them compete with larger chains by enhancing customer engagement and operational efficiency.
- Financial Services: Democratized AI brings robust fraud detection and personalized financial advice to smaller banks and credit unions. This improves security and customer service, enabling them to offer competitive services similar to those of larger financial institutions.
- Manufacturing: In manufacturing, AI democratization allows SMEs to implement predictive maintenance and quality control technologies. This reduces downtime, increases efficiency, and enables them to compete with larger counterparts in delivering high-quality products.
- Environment and Conservation: Accessible AI tools aid smaller organizations and nonprofits in environmental monitoring and conservation efforts. They can analyze data from various sources, such as satellite imagery, to track changes in ecosystems and biodiversity efficiently.
By making advanced AI technologies available to a wider range of users, democratization fosters innovation, bridges gaps in access, and empowers diverse sectors to solve complex problems in impactful ways.
Conclusion
As Large Language models' neurons grow in count, so their demand for more resources such as RAM memory and processor speed, specially in GPU processing, quantization brings them 'back to earth' allowing democratization regarding its access. As I've documented before, in my Macbook Pro M1, 16GB I can run up to 14B model, eating all my RAM yes, but it runs!
Remember, the bigger the model, the model elaborate their responses, more context, and maybe more 'noise', more verbose, which sometimes may not be a good thing, but I think it will depend greatly on how we communicate with the model through the prompt, the quality and precision of the prompt will play a big role on the quality of the response.
Let's keep exploring.
Chris.
Member discussion